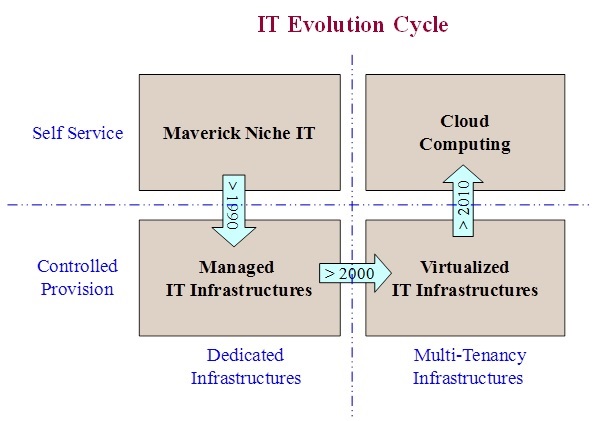
With 1,933 individual contributors and 164 organizations contributing to the release, Liberty offers finer-grained management controls, performance enhancements for large deployments and more powerful tools for managing new technologies such as containers in production environments ...
Quoting from its web-site:
“OpenStack Liberty, the 12th release of the open source software for building public, private, and hybrid clouds, offers unparalleled new functionality and enhancements. With the broadest support for popular data center technologies, OpenStack has become the integration engine for service providers and enterprises deploying cloud services.
With 1,933 individual contributors and 164 organizations contributing to the release, Liberty offers finer-grained management controls, performance enhancements for large deployments and more powerful tools for managing new technologies such as containers in production environments”
https://www.youtube.com/watch?v=e7r2-p8Mki4?autoplay=1
And the press release is quoted below:
Newest OpenStack® Release Expands Services for Software-Defined Networking, Container Management and Large Deployments
AUSTIN, Texas // October 15, 2015 — Cloud builders, operators and users unwrap a lengthy wish list of new features and refinements today with the Liberty release of OpenStack, the 12th version of the most widely deployed open source software for building clouds. With the broadest support for popular data center technologies, OpenStack has become the integration engine for service providers and enterprises deploying cloud services.
Available for download today, OpenStack Liberty answers the requests of a diverse community of the software’s users, including finer-grained management controls, performance enhancements for large deployments and more powerful tools for managing new technologies like containers in production environment.
Enhanced Manageability
Finer-grained access controls and simpler management features debut in Liberty. New capabilities like common library adoption and better configuration management have been added in direct response to the requests of OpenStack cloud operators. The new version also adds role-based access control (RBAC) for the Heat orchestration and Neutron networking projects. These controls allow operators to fine tune security settings at all levels of network and orchestration functions and APIs.
Finer-grained access controls and simpler management features debut in Liberty. New capabilities like common library adoption and better configuration management have been added in direct response to the requests of OpenStack cloud operators. The new version also adds role-based access control (RBAC) for the Heat orchestration and Neutron networking projects. These controls allow operators to fine tune security settings at all levels of network and orchestration functions and APIs.
Simplified Scalability
As the size and scope of production OpenStack deployments continue to grow—both public and private—users have asked for improved support for large deployments. In Liberty, these users gain performance and stability improvements that include the initial version of Nova Cells v2, which provides an updated model to support very large and multi-location compute deployments. Additionally, Liberty users will see improvements in the scalability and performance of the Horizon dashboard, Neutron networking Cinder block storage services and during upgrades to Nova’s compute services.
As the size and scope of production OpenStack deployments continue to grow—both public and private—users have asked for improved support for large deployments. In Liberty, these users gain performance and stability improvements that include the initial version of Nova Cells v2, which provides an updated model to support very large and multi-location compute deployments. Additionally, Liberty users will see improvements in the scalability and performance of the Horizon dashboard, Neutron networking Cinder block storage services and during upgrades to Nova’s compute services.
Extensibility to Support New Technologies
OpenStack is a single, open source platform for management of the three major cloud compute technologies; virtual machines, containers and bare metal instances. The software also is a favorite platform for organizations implementing NFV (network functions virtualization) services in their networking topologies. Liberty advances the software’s capabilities in both areas with new features like an extensible Nova compute scheduler, a network Quality of Service (QoS) framework and enhanced LBaaS (load balancing as a service).
OpenStack is a single, open source platform for management of the three major cloud compute technologies; virtual machines, containers and bare metal instances. The software also is a favorite platform for organizations implementing NFV (network functions virtualization) services in their networking topologies. Liberty advances the software’s capabilities in both areas with new features like an extensible Nova compute scheduler, a network Quality of Service (QoS) framework and enhanced LBaaS (load balancing as a service).
Liberty also brings the first full release of the Magnum containers management project. Out of the gate, Magnum supports popular container cluster management tools Kubernetes, Mesos and Docker Swarm. Magnum makes it easier to adopt container technology by tying into existing OpenStack services such as Nova, Ironic and Neutron. Further improvements are planned with new project, Kuryr, which integrates directly with native container networking components such as libnetwork.
The Heat orchestration project adds dozens of new resources for management, automation and orchestration of the expanded capabilities in Liberty. Improvements in management and scale, including APIs to expose what resources and actions are available, all filtered by RBAC are included in the new release.
1,933 individuals across more than 164 organizations contributed to OpenStack Liberty through upstream code, reviews, documentation and internationalization efforts. The top code committers to the Liberty release were HP, Red Hat, Mirantis, IBM, Rackspace, Huawei, Intel, Cisco, VMware, and NEC.
Focus on Core Services with Optional Capabilities
During the Liberty release cycle, the community shifted the way it organizes and recognizes upstream projects, which became known by community members as the “big tent.” Ultimately, the change allows the community to focus on a smaller set of stable core services, while encouraging more innovation and choice in the broader upstream ecosystem.
During the Liberty release cycle, the community shifted the way it organizes and recognizes upstream projects, which became known by community members as the “big tent.” Ultimately, the change allows the community to focus on a smaller set of stable core services, while encouraging more innovation and choice in the broader upstream ecosystem.
The core services, available in every OpenStack-Powered product or public cloud, center around compute (virtualization and bare metal), storage (block and object) and networking.
New projects added in the last six months provide optional capabilities for container management (supporting Kubernetes, Mesos and Docker Swarm) with Magnum, network orchestration with Astara, container networking with Kuryr, billing with CloudKitty and a Community App Catalog populated with many popular application templates. These new services join already recognized projects to support big data analysis, database cluster management, orchestration and more.
Supporting Quotes
“Liberty is a milestone release because it underscores the ability of a global, diverse community to agree on technical decisions, amend project governance in response to maturing software and the voice of the marketplace, then build and ship software that gives users and operators what they need. All of this happens in an open community where anyone can participate, giving rise to an extensible platform built to embrace technologies that work today and those on the horizon.”
— Jonathan Bryce, executive director, OpenStack Foundation
“Liberty is a milestone release because it underscores the ability of a global, diverse community to agree on technical decisions, amend project governance in response to maturing software and the voice of the marketplace, then build and ship software that gives users and operators what they need. All of this happens in an open community where anyone can participate, giving rise to an extensible platform built to embrace technologies that work today and those on the horizon.”
— Jonathan Bryce, executive director, OpenStack Foundation
“We use OpenStack because it delivers the core services we need in a production cloud platform that can extend to new technologies like containers. The ability to embrace emerging technologies as an open community rather than going solo is a primary reason why we’re sold on OpenStack.”
— Lachlan Evenson, cloud platform engineering, Lithium Technologies
— Lachlan Evenson, cloud platform engineering, Lithium Technologies
“OpenStack has emerged as an increasingly capable and widely deployed open cloud technology. The companies using it successfully are those that have done their research, engaged with the project’s community and deployed in manageable stages. We expect OpenStack-based service providers will outgrow the overall IaaS service provider market through 2019.”
— Al Sadowski, research director, 451 Research
— Al Sadowski, research director, 451 Research
“Notable Fortune 100 enterprises like BMW, Disney, and Wal-Mart have irrefutably proven that OpenStack is viable for production environments. These are regular companies, not firms that were born digital like Etsy, Facebook, and Netflix. OpenStack’s presence in the market is now accelerating, leveraging the success of these pioneers.”
— Lauren Nelson, senior analyst, Forrester Research, as written in “OpenStack Is Ready — Are You?,” a May 2015 report from Forrester Research.
— Lauren Nelson, senior analyst, Forrester Research, as written in “OpenStack Is Ready — Are You?,” a May 2015 report from Forrester Research.